Семантика играет все более важную роль в развитии инструментов для управления знаниями во многих отраслях бизнеса. Возможно, самые интересные разработки появляются в медиа.
Чтобы лучше понять как семантический поиск влияет на новости и соцмедиа, мы обсудили эти вопросы с Эваном Сендхаусом (Evan Sandhaus), ведущим архитектором семантических платформ в The New York Times Company, и Джефом Катлифом, CEO компании Lexalytics, специализирующейся на аналитике текстов.
Новостные медиа

Это морг The New York Times, коллекция тематических и биографических газетных вырезок с фотографиями из The Times и других изданий. Распологался в старой штабквартире Times на West 43rd Street, но недавно переехал.
«Все сайты борются за внимание людей», – говорит Сендхаус. Это специфическая особенность новостных служб и блогов. В конце концов, информация никому не будет полезной, если ее никто не прочитает. Поэтому задача состоит в том, чтобы контент могло найти максимальное количество людей.
Сама структура веб-пространства не совсем удобна для поиска контента. Изначально, интернет создавался на HTML – языке, предназначенном, в первую очередь, для отображения данных на веб-странице, а не для их описания. В результате, большая часть важных данных (заголовки, авторы, дата публикации) были форматированы с помощью HTML, но не были точно подписаны, как «заголовок», «автор», «дата публикации». Сендхаус считает, что «это создало сложности для самой экосистемы веб-пространства в определении естественной структуры контента». Пока веб-страницы форматируются для удобного просмотра человеком, машинам будет не просто понять смысл контента на странице. Это обесценивает его.
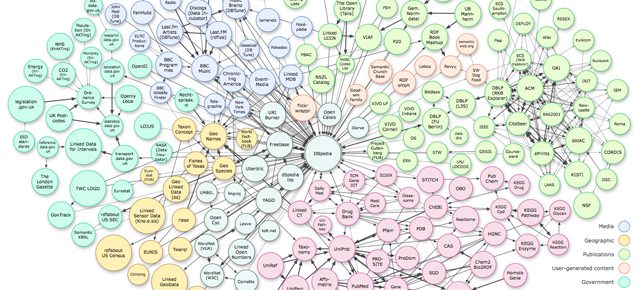
Итак, что же было сделано для того, чтобы уберечь контент от падения на самое дно глобального веб-океана? Множество людей работает над этой проблемой, но все они ходят вокруг концепции связанных данных (Linked Data). Связанные данные – это лучшие правила для распространения, отображения и создания связей между частями данных, информации и знаний в Семантическом вебе (Semantic Web).
С момента основания The New York Times постоянно участвует в разработке Semantic Web. С конца XIX века это издание имеет хорошо организованный влиятельный новостной словарь для архивации вырезок из New York Times и других изданий. Эти архивы создавались для того, чтобы журналисты могли получить доступ к историческим документам по различным темам, связанным с тематикой репортажа. Вряд ли кто-то представлял, что этот хорошо организованный архив с огромным количеством полезных данных сильно пригодится The Times через 100 лет во времена бурного роста семантических технологий.
В 2009 The Times начали публиковать этот словарь, включающий в себя информацию об известных людях, организациях, местах и описания к ним в формате связанных открытых данных (linked open data), позволяя другим взаимодействовать с этими данными, открывая мир возможностей их нового применения. К сентябрю 2010 года было сформировано 203 набора данных (datasets), включая данные The Times, опубликованные в формате связаных данных.
Создание стандартов сильно помогает в улучшении связанности интернета, как пространства. Работая над объединением информации, The World Wide Web Consortium (W3C) продолжает разработку стандартов для Семантического Веба, в частности популяризируя формат RDF, который позволяет вставлять в веб-документы метаданные, такие как заголовок, автор, дата и другие атрибуты новостного материала. Это дает возможностям пользователям выявлять специфические разделы веб-страницы, что делает информацию более полезной.
Тем не менее, RDF имеет свои недостатки. В частности, в нем можно давать разные названия одним и тем же данным. Например, “заголовок” может также называться “заглавием”, “schlagzeile” (на немецком) и “intestazione” (по-итальянски).
The New York Times надеется облегчить остроту этой проблемы. В октябре 2010 The Times и International Press Telecommunications Council начали работу над созданием стандарта для издателей, который бы позволял вставлять структурные метаданные в HTML. Этот фреймворк называется rNews. Благодаря этому стандарту, поисковые системы, агрегаторы и социальные сайты получат доступ к более структурированным данным. Проект только начался, но, по мнению Эвана, уже в ближайшие месяцы можно ожидать конкретных результатов.
Social Media

Социальные медиа – еще одна часть веб-пространства, в которой контент играет важную роль. Например, Twitter генерирует более 110 миллионов сообщений в день, а половина из 500 миллионов пользователей Facebook заходит туда каждый день.
По мере того, как пользователи тратят все больше времени на социальные сети, бренды понимают важность присутствия там. Как только бизнес начал измерять ROI своих кампаний в соцмедиа, средства аналитики вышли на первый план.
Оглядываясь на последние несколько лет, Джеф Катлиф, CEO Lexalytics, с уверенностью говорит о возрастающей роли анализа общественного мнения (Sentiment analysis) в оценке эффективности работы брендов в соцмедиа.
Существуют два основных аспекта бренд-ориентированной коммуникации на социальных платформах. В то время, как бренды отравляют свои маркетинговые сообщения через социальные каналы, потребители обсуждают эти бренды и продукты в своих постах. Как следствие, существует два основных направления, в которых бренды используют семантику.
- Анализ настроения потребителей. Бренды хотят знать, что о них говорят потребители. Все большее количество сервисов способны анализировать сообщения пользователей и определять их реальное отношение к продукту или бренду. Одни сервисы могут различать тональность высказываний о продукте или услуге. Другие, более продвинутые, могут определить не очевидное отношение, завуалированное в текстовом сообщении пользователя. Например, сервис Viralheat способен достаточно точно находить пользователей в социальных медиа, почти готовых к приобретению того или иного товара/услуги. Подобные сервисы позволяют брендам отсеивать нерелевантные сообщения и фокусироваться на целевой аудитории.
- Последовательность сообщений. На данный момент мониторинг настроений потребителей не является мощной технологией. Но есть еще один, более отточенный механизм применения семантического анализа текста: мониторинг последовательности в сообщениях самого бренда. Джеф Катлиф подчеркивает, что для бренда очень важно «звучать так, как будто все сообщения о продуктах и услугах исходят из одних уст и четко понимать то, как эти сообщения доходят до пользователей». Исторически сложилось так, что бренды придают важную роль тому, насколько сообщения о товарах и услугах последовательны и просты для понимания (копирайтеры, привет!) , и социальные медиа стали очередным каналом для коммуникации. Однако сейчас, благодаря интернету, количество сообщений от бренда постоянно увеличивается, и семантический анализ позволяет брендам анализировать их качество и последовательность. Подобный анализ также помогает в формировании стратегии коммуникации на будущее.
Хотя и сейчас семантический анализ играет важную роль в мониторинге медиа, Джеф Катлиф считает, что в ближайшее семантика станет неотъемлемым элементом социального поиска для пользователей. Поисковые системы внутри социальных сайтов должны будут интегрировать семантические технологии, чтобы выдавать релевантные результаты. К примеру, если пользователь ищет “индийская кухня”, поиск по ключевым словам будет не так эффективен, как поиск на основе семантического анализа. «Допустим, вы интересуетесь индийской кухней», – объясняет Катлиф, – «Представьте себе твит `это была лучшая тика масала, которую я когда-либо ел`. Поиск по ключевым словам будет бесполезен, так как в сообщении нет ключевых слов “индийская кухня”. А вот семантический анализ позволит идентифицировать большого любителя карри и индийской кухни, потому что учитывает большее количество данных».
Lexalytics разрабатывает технологии, которые позволят анализировать подобные запросы, и в ближайшее время планирует продемонстрировать свои наработки. «Представьте себе классификацию всей Википедии», – говорит Катлиф, – «Если вы классифицируете все данные Вики, то начнете видеть взаимосвязи. Например то, что тика масала относится к индийской кухне».
Выводы
По мере развития семантических технологий данные в веб-пространстве будут становиться все выразительнее и полезнее. Традиционные издания, такие как The New York Times, уже видят выгоду от участия в программе Семантического Веба. Теперь они могут использовать данные других людей в собственных статьях. В то же время социальному поиску будет полезно понимание семантических связей, что даст возможность повысить качество аналитики для брендов и улучшить социальные платформы для конечных пользователей.
Источник: mashable.com
Теги: Facebook, Lexalytics, Linked Data, RDF, rNews, Semantic Web, Sentiment analysis, The New York Times Company, Twitter, Viralheat, W3C